Desde finales de 2018 estoy cursando un Bootcamp en Keepcoding de Big Data y machine learning. El temario promete y por ahora estoy contento con lo aprendido. Es un poco duro volver ponerse a estudiar de esta manera después de muchos años, pero lo voy llevando bien. Por suerte en este oficio siempre tenemos que estar aprendiendo, por lo que no me pilla oxidado del todo.
Así que he decido aprovechar este blog que nunca termino de arrancar para ir plasmando algunos de los conocimientos que estoy adquiriendo. Puede que a alguien le pueda servir de ayuda en algún momento, a mi me sirve para repasar conocimientos, para tenerlo documentado para mi mismo y para ampliar de alguna forma lo que me han enseñado.
Lo primero que voy a plasmar es como crear y configurar un cluster de Hadoop con docker. Voy a intentar hacer todo desde 0 y en futuras entradas de este blog iré ampliando el cluster con Hive, Spark, Kafka, etc y también incluyendo ejemplos de procesamiento de información con toda esta tecnología.
En un principio había pensado hacer todo esto con Vagrant, por diferir un poco como lo he hecho en clase, pero al final va a ser lo mismo y me resulta más práctico hacerlo con Docker. Ademán en un futuro puedo ampliar la información integrándolo con Kubernetes o Swarm. Posteriormente también quiero hacerlo todo con Google Cloud y Amazon AWS. Son muchas cosas las que quiero hacer, espero llegar a todo.
Creando nuestra imagen base
De todos los ficheros que iré generando los voy a ir generando en un repositorio de GitHub. Como el mismo repositorio me irá sirviendo para muchos artículos, iré haciendo ramas por cada artículo para que se pueda obtener los ficheros de cada artículo.
Primero voy a hacer un Dockerfile con una imagen base que deje Hadoop instalado y configurado para usar en cualquier maquina en modo Stand Alone (todo en un solo servidor) y a partir de ahí generaré otros Dockerfiles para los nodos master, slave, etc.
Explico paso a paso el contenido del Dockerfile:
Primero indicamos que nos basamos en la imagen de Ubuntu 16.04 como imagen base.
FROM ubuntu:16.04
MAINTAINER irm
Instalamos un servidor SSH y la JDK8
RUN apt-get update && apt-get install -y openssh-server openjdk-8-jdk wget
Ahora nos bajamos el software de Hadoop y lo dejamos en /usr/local/hadoop
# install hadoop 2.7.2
RUN wget http://apache.rediris.es/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz && \
tar -xzvf hadoop-2.7.7.tar.gz && \
mv hadoop-2.7.7 /usr/local/hadoop && \
rm hadoop-2.7.7.tar.gz
Establecemos las variables de entorno JAVA_HOME apuntando a la ruta del JDK, HADOOP_HOME apuntando a la ruta en la que hemos copiado Hadoop e incluimos en la variable PATH las rutas con los binarios y scripts para gestionar Hadoop.
# set environment variable
ENV JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
ENV HADOOP_HOME=/usr/local/hadoop
ENV PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin
Creamos las claves ssh necesarias para que se comunique el nodo master con los nodos slaves. Al tener todos las mismas claves e incluirlas como claves autorizadas, el acceso ssh entre los distintos nodos está garantizado.
# ssh without key
RUN ssh-keygen -t rsa -f ~/.ssh/id_rsa -P '' && \
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
Creamos los directorios para los namenodes, los datanodes y los logs de Hadoop
RUN mkdir -p ~/hdfs/namenode && \
mkdir -p ~/hdfs/datanode && \
mkdir $HADOOP_HOME/logs
Copiamos los ficheros de configuración y scripts que tenemos en el directorio config al directorio /tmp. De ahí los vamos moviendo cada uno a su ubicación final. Más adelante explico cada fichero y su contenido.
COPY config/* /tmp/
RUN mv /tmp/ssh_config ~/.ssh/config && \
mv /tmp/hadoop-env.sh /usr/local/hadoop/etc/hadoop/hadoop-env.sh && \
mv /tmp/hdfs-site.xml $HADOOP_HOME/etc/hadoop/hdfs-site.xml && \
mv /tmp/core-site.xml $HADOOP_HOME/etc/hadoop/core-site.xml && \
mv /tmp/mapred-site.xml $HADOOP_HOME/etc/hadoop/mapred-site.xml && \
mv /tmp/yarn-site.xml $HADOOP_HOME/etc/hadoop/yarn-site.xml && \
mv /tmp/slaves $HADOOP_HOME/etc/hadoop/slaves && \
mv /tmp/start-hadoop.sh ~/start-hadoop.sh
RUN chmod +x ~/start-hadoop.sh && \
chmod +x $HADOOP_HOME/sbin/start-dfs.sh && \
chmod +x $HADOOP_HOME/sbin/start-yarn.sh Formateamos el sistema de ficheros de hadoop.
RUN /usr/local/hadoop/bin/hdfs namenode -format
Como proceso de los contenedores configuramos el demonio de ssh. As’el nodo master podrá acceder a los nodos slave para arrancar los procesos de Hadoop necesarios para que formen parte del cluster.
CMD [ "sh", "-c", "service ssh start; bash"]
Por último dejamos abiertos unos cuantos puertos. En principio no son necesarios todos, pero los dejo así por si en un futuro los necesito.
# Hdfs ports
EXPOSE 9000 50010 50020 50070 50075 50090
EXPOSE 9871 9870 9820 9869 9868 9867 9866 9865 9864
# Mapred ports
EXPOSE 19888
#Yarn ports
EXPOSE 8030 8031 8032 8033 8040 8042 8088 8188
#Other ports
EXPOSE 49707 2122
Este sería el fichero Dockerfile completo. Así es más fácil copiarlo y pegarlo si quieres probarlo.
FROM ubuntu:16.04
MAINTAINER irm
WORKDIR /root
# install openssh-server, openjdk and wget
RUN apt-get update && apt-get install -y openssh-server openjdk-8-jdk wget
# install hadoop 2.7.2
RUN wget http://apache.rediris.es/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz && \
tar -xzvf hadoop-2.7.7.tar.gz && \
mv hadoop-2.7.7 /usr/local/hadoop && \
rm hadoop-2.7.7.tar.gz
# set environment variable
ENV JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
ENV HADOOP_HOME=/usr/local/hadoop
ENV PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin
# ssh without key
RUN ssh-keygen -t rsa -f ~/.ssh/id_rsa -P '' && \
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
RUN mkdir -p ~/hdfs/namenode && \
mkdir -p ~/hdfs/datanode && \
mkdir $HADOOP_HOME/logs
COPY config/* /tmp/
RUN mv /tmp/ssh_config ~/.ssh/config && \
mv /tmp/hadoop-env.sh /usr/local/hadoop/etc/hadoop/hadoop-env.sh && \
mv /tmp/hdfs-site.xml $HADOOP_HOME/etc/hadoop/hdfs-site.xml && \
mv /tmp/core-site.xml $HADOOP_HOME/etc/hadoop/core-site.xml && \
mv /tmp/mapred-site.xml $HADOOP_HOME/etc/hadoop/mapred-site.xml && \
mv /tmp/yarn-site.xml $HADOOP_HOME/etc/hadoop/yarn-site.xml && \
mv /tmp/slaves $HADOOP_HOME/etc/hadoop/slaves && \
mv /tmp/start-hadoop.sh ~/start-hadoop.sh
RUN chmod +x ~/start-hadoop.sh && \
chmod +x $HADOOP_HOME/sbin/start-dfs.sh && \
chmod +x $HADOOP_HOME/sbin/start-yarn.sh
# format namenode
RUN /usr/local/hadoop/bin/hdfs namenode -format
CMD [ "sh", "-c", "service ssh start; bash"]
# Hdfs ports
EXPOSE 9000 50010 50020 50070 50075 50090
EXPOSE 9871 9870 9820 9869 9868 9867 9866 9865 9864
# Mapred ports
EXPOSE 19888
#Yarn ports
EXPOSE 8030 8031 8032 8033 8040 8042 8088 8188
#Other ports
EXPOSE 49707 2122
La configuración del cluster
Bueno, vamos a ver los ficheros de configuración que se copian dentro de la imagen que acabamos de configurar. La mayoría de ficheros de configuración de Hadoop son ficheros XML y tienen una estructura de este tipo:
<?xml version="1.0"?>
<configuration>
<property>
<name>param1</name>
<value>value1</value>
</property>
<property>
<name>param2</name>
<value>value2</value>
<description>description 2</description>
</property>
</configuration>
core-site.xml En este fichero vamos a configurar la localización del NameNode. En nuestro caso será una máquina que denominaremos hadoop-master.
<?xml version="1.0"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-master:9000/</value>
</property>
</configuration>
hdfs-site.xml En este fichero configuramos algunas propiedades del sistema de ficheros.
<?xml version="1.0"?>
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///root/hdfs/namenode</value>
<description>NameNode directory for namespace and transaction logs storage.</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///root/hdfs/datanode</value>
<description>DataNode directory</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
mapred-site.xml En este fichero se el MapReduce. En nuestro caso configuraremos el MapReduce de nuestro Hadoop al nuevo al framework MapReduce Yarn.
<?xml version="1.0"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml En este fichero configuramos el framework de MarReduce Yarn. Con estos parámetros indicamos que se habilite la fase de Suffle para que se pueda hacer entre las fases de Map y Reduce ya que YARN por defecto no lo incluye. También indicamos que el ResourceManager estará en hadoop-master
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-master</value>
</property>
</configuration>
slaves Este fichero es el único que tenemos que no es XML. En este fichero se indican los nodos que tendrá el cluster, indicando cada uno en una línea. En nuestro caso indicamos el master y dos slaves.
hadoop-master
hadoop-slave1
hadoop-slave2
Creando nuestra imagen del nodo master
Vamos a crear otro fichero Dockerfile para la imagen del nodo master del cluster. En este caso es más sencillo que el anterior. De hecho esta imagen se basa en la imagen base que hemos creado antes.
FROM irm/hadoop-cluster-base
MAINTAINER irm
WORKDIR /root
ADD config/bootstrap.sh /etc/bootstrap.sh
RUN chown root:root /etc/bootstrap.sh
RUN chmod 700 /etc/bootstrap.sh
ENV BOOTSTRAP /etc/bootstrap.sh
CMD ["/etc/bootstrap.sh", "-d"]
Como se puede ver lo que hace es copiar el script bootstrap que se encargará de arrancar el servicio de ssh y nuestro cluster. Al final lanza un proceso de bash para que el contenedor se mantenga en ejecución y podamos ver después que se ha lanzado todo correctamente. Este es el contenido del script:
#!/bin/bash
rm /tmp/*.pid
service ssh start
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh
bash
Probando nuestro cluster
Ya tenemos casi todo para tener nuestro cluster funcionando. Para generar las imágenes y lanzar el cluster tenemos el siguiente script de bash:
#!/bin/bash
# create base hadoop cluster docker image
docker build -f docker/base/Dockerfile -t irm/hadoop-cluster-base:latest docker/base
# create master node hadoop cluster docker image
docker build -f docker/master/Dockerfile -t irm/hadoop-cluster-master:latest docker/master
# the default node number is 3
N=${1:-3}
docker network create --driver=bridge hadoop &> /dev/null
# start hadoop slave container
i=1
while [ $i -lt $N ]
do
docker rm -f hadoop-slave$i &> /dev/null
echo "start hadoop-slave$i container..."
docker run -itd \
--net=hadoop \
--name hadoop-slave$i \
--hostname hadoop-slave$i \
irm/hadoop-cluster-base
i=$(( $i + 1 ))
done
# start hadoop master container
docker rm -f hadoop-master &> /dev/null
echo "start hadoop-master container..."
docker run -itd \
--net=hadoop \
-p 50070:50070 \
-p 8088:8088 \
--name hadoop-master \
--hostname hadoop-master \
-v $PWD/data:/data \
irm/hadoop-cluster-master
# get into hadoop master container
docker exec -it hadoop-master bash
¿Que hace este script?
- En primer lugar genera la imágenes de docker a partir de los ficheros Dockerfile.
- Después crea una red docker para uso del los nodos del cluster.
- Crea dos contenedores a partir de la imagen base que acabamos de crear.
- Crea un contenedor para el nodo master.
- Abre una sesión de bash en el nodo master.
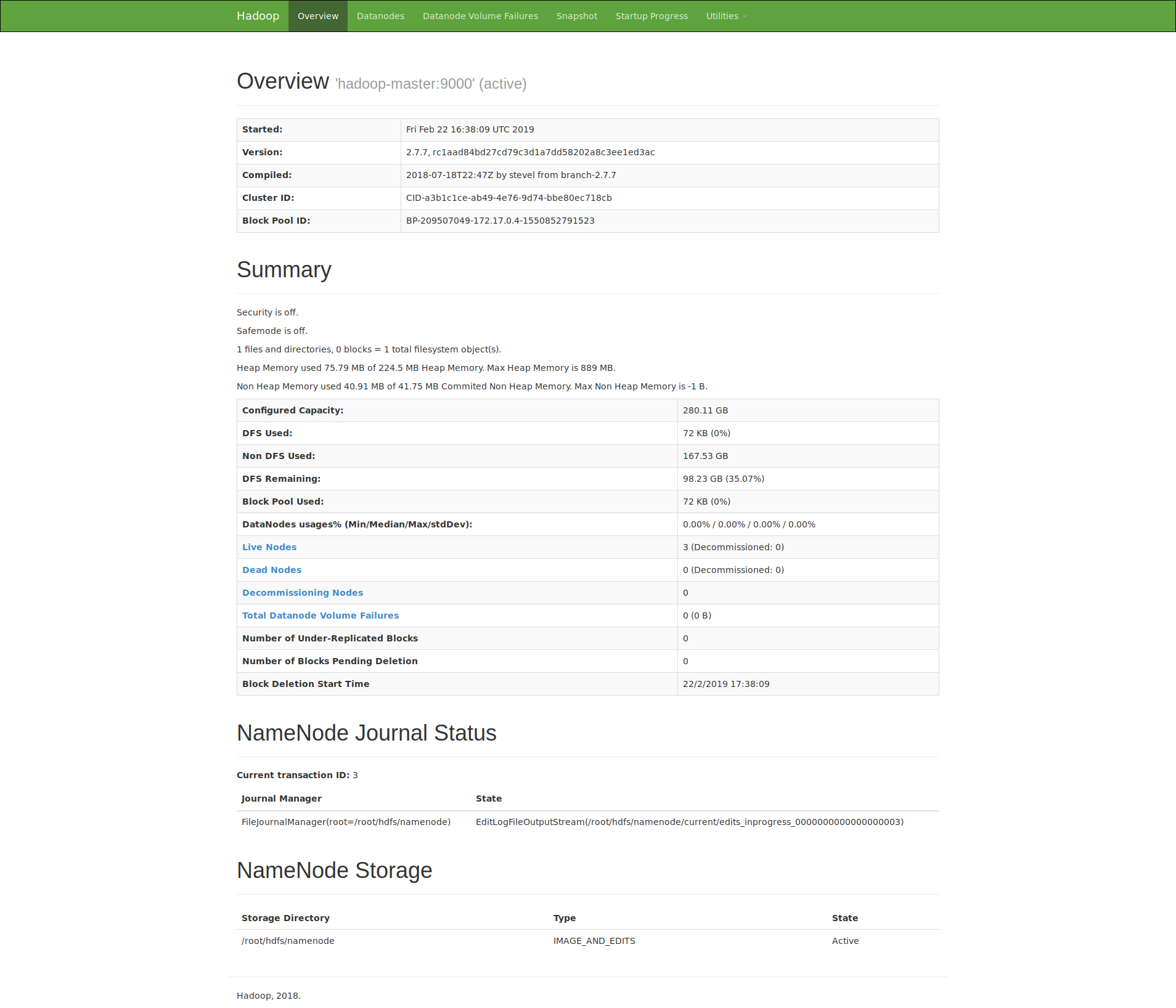
Tardará unos segundos, pero cuando termine de arrancar el cluster podemos entrar a la web que provee Hadoop para ver el estado del cluster.
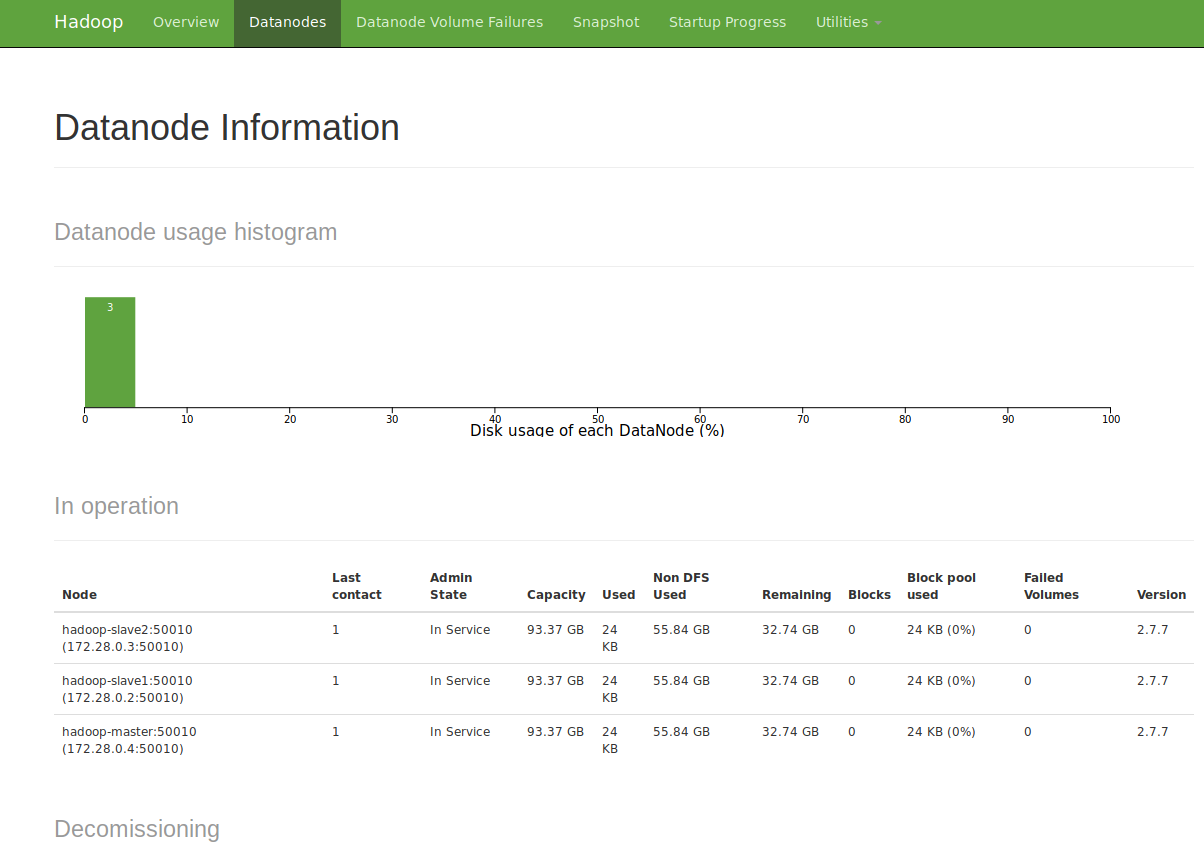
Si pulsamos en la sección de Datanodes podremos ver los tres nodos de nuestro cluster. El master y los dos slaves
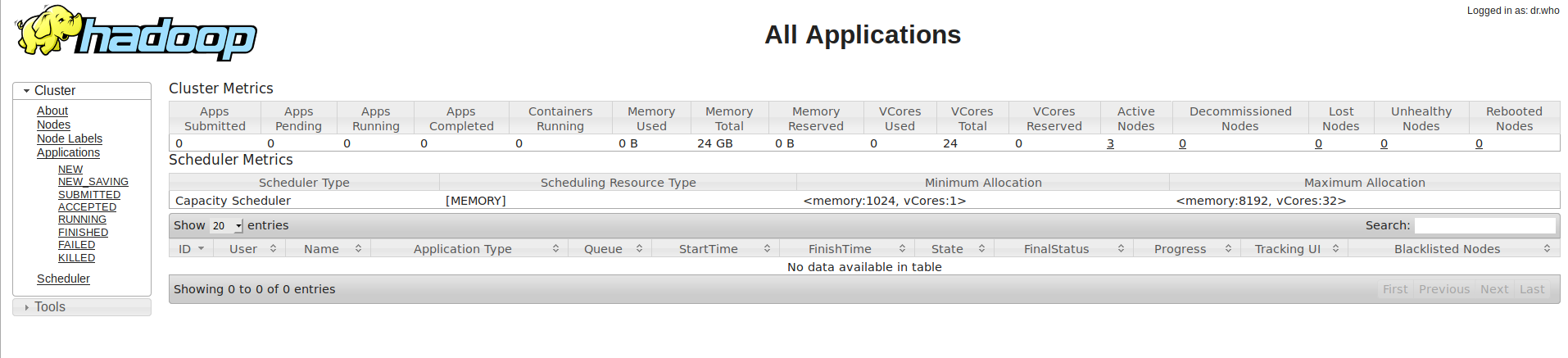
También podemos ver la el cluster Yarn y la información que ofrece de los trabajos
Próximos pasos
En futuras entradas ampliaremos nuestro cluster integrando Hive. Veremos como lanzar procesos de MapReduce y de Hive. También quiero integrar Spark y lanzar trabajos realizado en Scala, pero para eso queda un poco todavía.
Mi idea es ir usando el mismo repositorio de Github para la serie de artículos y que cada artículo tenga su propia rama. Para este artículo la rama es create_hadoop_cluster, así que si clonas el repositorio recuerda cambiar a la rama create_hadoop_cluster para tener los ficheros correspondientes a este artículo.
git clone https://github.com/ivanrumo/KC_Practica_Big-Data-Architecture_docker.git
cd KC_Practica_Big-Data-Architecture_docker
git checkout create_hadoop_cluster
Así tendrás todo el contenido disponible y funcional. Solo hay que ejecutar el script start-cluster.sh y hará toda la magia.